
3.4.3 Step 2: Loop Pipelining
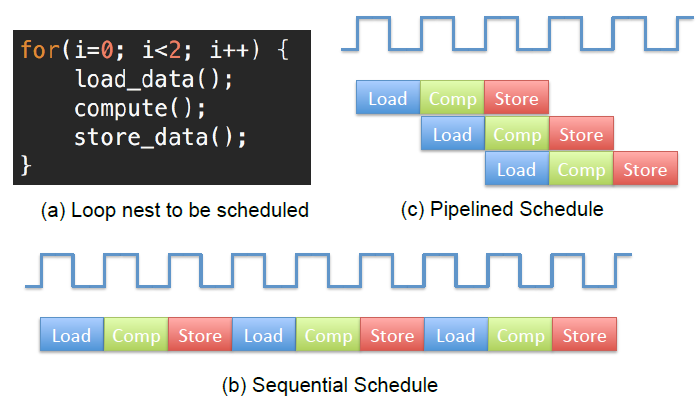
(Ask a Question)In this section, you will use loop pipelining to improve the throughput of the hardware generated by SmartHLS™. Loop pipelining allows a new iteration of the loop to be started before the current iteration has finished. By allowing the execution of the loop iterations to be overlapped, a higher throughput can be achieved. The amount of overlap is controlled by the initiation interval (II). The II indicates how many cycles are required before starting the next loop iteration. Thus, an II of 1 means a new loop iteration can be started every clock cycle, which is the best that can be achieved. The II needs to be larger than 1 in other cases, such as when there is a resource contention (multiple loop iterations need the same resource in the same clock cycle) or when there are loop-carried dependencies (the output of a previous iteration is needed as an input to the subsequent iteration). Resource contention commonly happens with memory accesses to dual-port block RAMs, which can only perform two memory accesses per cycle.
The following figure shows an example of loop pipelining. The following figure(b) shows the sequential loop, where a new loop iteration can start every three clock cycles (II=3), and the loop takes nine clock cycles to finish the final write. The following figure(c) shows the pipelined loop. In this example, there are no resource contentions or data dependencies. Therefore, the pipelined loop can start a new iteration every clock cycle (II=1) and takes only five clock cycles to finish the final write. As shown in this example, loop pipelining can significantly improve your circuit's performance, when there are no data dependencies or resource contentions.
Follow the same procedure you used in the previous part of this tutorial (include the source files for part 2 and target MPF100T-FCVG484I), and create a new SmartHLS project for part 2. Once the project is created, open the part 2 source file sobel.cpp. With the Sobel filter, since each pixel of the output is dependent only on the input image and the constant matrices Gx and Gy, the calculation of each pixel would be pipelined. The loop pipeline pragma in front of the loop, #pragma HLS loop pipeline, tells SmartHLS to pipeline the loop and take advantage of loop parallelism:
#pragma HLS loop pipeline for (int i = 0; i < (HEIGHT – 2) * (WIDTH – 2); i++) {
You will notice that the pair of nested loops in part 1 (previously using i and j) have been flattened into one for a loop. The nested loops have been flattened to allow the application of loop pipelining on the entire loop body. Otherwise, when loop pipelining is applied on a nested outer loop, SmartHLS automatically unrolls the inner loops, which would not be possible with 512 iterations. See Appendix: Loop Pipelining in Part 1 vs. Part 2 for more details.
- You can now synthesize the design by clicking on the Compile Software to Hardware icon in the toolbar. In the Console window, you should see messages similar to the following:

Info: Resource constraint limits initiation interval to 4. Resource 'in_external_memory_port' has 8 uses per cycle but only 2 units available. +--------------------------------------+---------------------------+---------------------+ | Operation | Location | Competing Use Count | +--------------------------------------+---------------------------+---------------------+ | 'load' (8b) operation for array 'in' | line 30 of sobel.cpp | 1 | | 'load' (8b) operation for array 'in' | line 30 of sobel.cpp | 2 | | 'load' (8b) operation for array 'in' | line 30 of sobel.cpp | 3 | | 'load' (8b) operation for array 'in' | line 30 of sobel.cpp | 4 | | 'load' (8b) operation for array 'in' | line 30 of sobel.cpp | 5 | | 'load' (8b) operation for array 'in' | line 30 of sobel.cpp | 6 | | 'load' (8b) operation for array 'in' | line 30 of sobel.cpp | 7 | | 'load' (8b) operation for array 'in' | line 30 of sobel.cpp | 8 | +--------------------------------------+---------------------------+---------------------+ | | Total # of Competing Uses | 8 | +--------------------------------------+---------------------------+---------------------+
These messages indicate that SmartHLS cannot achieve an II of 1 (highest throughput) due to resource conflicts – there are eight loads from the same RAM in the loop body. Since RAM blocks are dual-ported on an FPGA, we need four cycles to perform eight loads. Therefore, SmartHLS needs to schedule four cycles between successive iterations of the loop (an initiation interval of 4).
- You can visualize the 8 memory loads in the pipeline using the SmartHLS schedule viewer. Click on the Launch Schedule Viewer icon . Double-click on

sobel_filter, then in the Control Flow Graph, you will see a basic block calledBB_for_body. Double-clickBB_for_bodyto reveal the loop pipeline schedule, similar to what is shown in the following figure. Horizontally from left to right shows the operations performed on successive clock cycles, and vertically going down shows successive loop iterations. Here, you can see that the II of the loop is 4 and that a new loop iteration starts every 4 cycles. You can also see the instructions that are scheduled in each cycle for each loop iteration. All instructions that are shown in the same column are executed in the same cycle. Now scroll to the far right in the schedule viewer. The dark black rectangle on the far right illustrates what the pipeline looks like in a steady-state. In steady-state, three iterations of the loop are “in-flight” at once. In steady-state, you can see that there are two loads in cycle 8 from iteration 1 (the second row down), two loads in cycle 9 from iteration 1, two loads in cycle 10 from iteration 2 (third row down), and two loads in cycle 11 from iteration 2. Thus the eight loads are spread out over four cycles, making the Initiation Interval = 4.Figure 3-19. Loop Pipeline Schedule for the Sobel filter. 
- Exit the schedule viewer and simulate the design in ModelSim by clicking on the SW/HW Co-Simulation icon on the toolbar. You should see Console output similar to the following:

... # Cycle latency: 1040413 # ** Note: $finish : ../simulation/cosim_tb.sv(279) # Time: 20808290 ns Iteration: 1 Instance: /cosim_tb # End time: 00:04:28 on Jun 30,2021, Elapsed time: 0:00:37 # Errors: 0, Warnings: 0 ... Info: Verifying RTL simulation ... Retrieving hardware outputs from RTL simulation for sobel_filter function call 1. PASS! ... Number of calls: 1 Cycle latency: 1,040,413 SW/HW co-simulation: PASS
Observe that the loop pipelining has dramatically improved the cycle latency for the design, reducing it from 3,392,549 cycles to 1,040,413 cycles in total. - Use Microchip’s Libero® to
map the design onto the PolarFire® FPGA by clicking on the
Synthesize Hardware to FPGA icon on the toolbar. Once the synthesis run finishes, examine the FPGA speed (FMax) and area data from the summary.results.rpt report file. You should see results similar to the following:

====== 2. Timing Result ====== +--------------+---------------+-------------+-------------+----------+-------------+ | Clock Domain | Target Period | Target Fmax | Worst Slack | Period | Fmax | +--------------+---------------+-------------+-------------+----------+-------------+ | clk | 10.000 ns | 100.000 MHz | 7.288 ns | 2.712 ns | 368.732 MHz | +--------------+---------------+-------------+-------------+----------+-------------+ ... ====== 3. Resource Usage ====== +--------------------------+---------------+--------+------------+ | Resource Type | Used | Total | Percentage | +--------------------------+---------------+--------+------------+ | Fabric + Interface 4LUT* | 778 + 0 = 778 | 108600 | 0.72 | | Fabric + Interface DFF* | 535 + 0 = 535 | 108600 | 0.49 | | I/O Register | 0 | 852 | 0.00 | | User I/O | 0 | 284 | 0.00 | | uSRAM | 0 | 1008 | 0.00 | | LSRAM | 0 | 352 | 0.00 | | Math | 0 | 336 | 0.00 | +--------------------------+---------------+--------+------------+