
3.5.2.8 Inferring Streaming Hardware via Producer-Consumer Pattern with Threads
(Ask a Question)The producer-consumer pattern is a well-known concurrent programming paradigm. It typically comprises a finite-size buffer and two classes of threads, a producer and a consumer. The producer stores data into the buffer and the consumer takes data from the buffer to process. The producer must wait until the buffer has space before it can store new data, and the consumer must wait until the buffer is not empty before it can take data. The waiting is usually realized with the use of a semaphore.
The pseudocode for a producer-consumer pattern with two threads is shown below.
producer_thread {
while (1) {
// produce data
item = produce();
// wait for an empty space in the buffer
sem_wait(numEmpty);
// store item to buffer
lock(mutex);
write_to_buffer;
unlock(mutex);
// increment number of full spots in the buffer
sem_post(numFull);
}
}
consumer_thread {
while (1) {
// wait until buffer is not empty
sem_wait(numFull);
// get data from buffer
lock(mutex);
read_from_buffer;
unlock(mutex);
// increment number of empty spots in the buffer
sem_post(numEmpty);
// process data
consume(item);
}
}
In a producer-consumer pattern, the independent producer and consumer threads are continuously running, thus they contain infinite loops. Semaphores are used to keep track of the number of spots available in the buffer and the number of items stored in the buffer. A mutex is also used to enforce mutual exclusion on accesses to the buffer.
The producer-consumer pattern is an ideal software approach to describing streaming hardware. Streaming hardware is always running, just as the producer-consumer threads shown above. Different streaming hardware modules execute concurrently and independently, as with the producer-consumer threads. SmartHLS™ supports the use of threads, hence the producer-consumer pattern expressed with threads can be directly synthesized to streaming hardware. Our easy-to-use FIFO library provides the required buffer between a producer and a consumer, without the user having to specify the low-level intricacies of using semaphores and mutexes.
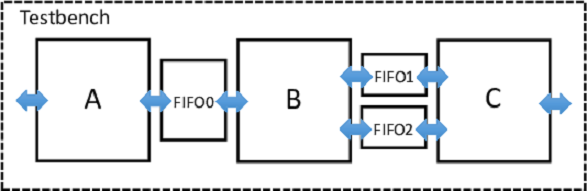
An example pseudo code with three kernels, where function A is a producer to function B (B is a consumer to A), and function B is a producer to C (C is a consumer to B) is shown below.
void A(hls::FIFO<int> *FIFO0) {
...
#pragma HLS loop pipeline
while (1) {
// do some work
...
// write to output FIFO
FIFO0->write(out);
}
}
void B(hls::FIFO<int> *FIFO0, hls::FIFO<int> *FIFO1, hls::FIFO<int> *FIFO2) {
...
#pragma HLS loop pipeline
while (1) {
// read from input FIFO
int a = FIFO0->read();
// do some work
...
// write to output FIFOs
FIFO1->write(FIFO1, data1);
FIFO2->write(FIFO2, data2);
}
}
void C(hls::FIFO<int> *FIFO1, hls::FIFO<int> *FIFO2) {
...
#pragma HLS loop pipeline
while (1) {
// read from input FIFOs
int a = FIFO1->read();
int b = FIFO2->read();
// do some work
...
}
}
...
void top() {
hls::FIFO<int> FIFO0;
hls::FIFO<int> FIFO1;
hls::FIFO<int> FIFO2;
hls::thread<void>(A, &FIFO0);
hls::thread<void>(B, &FIFO0, &FIFO1, &FIFO2);
hls::thread<void>(C, &FIFO1, &FIFO2);
}
Each kernel contains an infinite loop, which keeps the loop body continuously running. We pipeline this loop, to create a streaming circuit. The advantage of using loop pipelining, versus pipelining the entire function (with function pipelining), is that there can also be parts of the function that are not streaming (only executed once), such as for performing initializations. The top function forks a separate thread for each of the kernel functions. The user does not have to specify the number of times the functions are executed – the threads automatically start executing when there is data in their input FIFOs. This matches the always running behaviour of streaming hardware. The multi-threaded code above can be compiled, concurrently executed, and debugged using standard software tools (e.g., gcc, gdb). When compiled to hardware with SmartHLS, the following hardware architecture is created:
Another advantage of using threads in SmartHLS is that one can also easily replicate streaming hardware. In SmartHLS, each thread is mapped to a hardware instance, hence forking multiple threads of the same function creates replicated hardware instances that execute concurrently. For instance, if the application shown above is completely parallelizable (i.e., data-parallel), one can exploit spatial hardware parallelism by forking two threads for each function, to create the architecture shown below. This methodology therefore allows exploiting both spatial (replication) and pipeline hardware parallelism all from software.
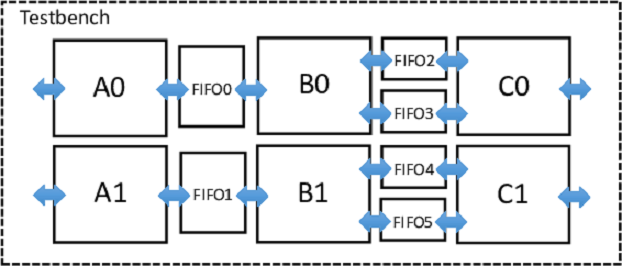
For replication, some HLS tools may require the hardware designer to manually instantiate a synthesized core multiple times and also make the necessary connections in HDL. This is cumbersome for a hardware engineer and infeasible for a software engineer. Another approach is to use a system integration tool, which allow users to connect hardware modules via a schematic-like block design entry methodology. This, also, is a foreign concept in the software domain. Our methodology uses purely software concepts to automatically create and connect multiple concurrently executing streaming modules.
To create the replicated architecture shown above, one simply has to change the top function as the following:
#define NUM_THREADS 2 void top() { int i; hls::FIFO<int> FIFO0[NUM_THREADS], FIFO1[NUM_THREADS], FIFO2[NUM_THREADS]; for (i=0; i<NUM_THREADS; i++) { hls::thread<void>(A, &FIFO0[i]); hls::thread<void>(B, &FIFO0[i], &FIFO1[i], &FIFO2[i]); hls::thread<void>(C, &FIFO1[i], &FIFO2[i]); } }
This simple, yet powerful technique allows creating multiple replicated streaming hardware modules directly from standard software. As this is a purely standard software solution, without requiring any tool specific pragmas, the concurrent execution behaviour of the replicated kernels can be modeled from software.