
Using DoubleBuffer and SharedBuffer in a multi-threaded dataflow design
(Ask a Question)We will use a more complete example to further demonstrate how to use DoubleBuffer and SharedBuffer in a multi-threaded dataflow design, and how the buffer classes enable parallelism between the dataflow threads.
Say we have a continuous input stream, every 2048 elements in the stream is considered as a segment. We are going to sort each 2048-element segment of the input stream and write the sorted segments to an output stream.

For better throughput, we can overlap the three processing stages with multi-threading, and use DoubleBuffer or SharedBuffer to synchronize the accesses to the shared buffer between upstream and downstream threads. Compared to SharedBuffer, each DoubleBuffer contains two copies of storage instead of one, which reduces the delay that a processing stage waits for the buffer to become available.
The code below describes the design in C++:
#include <hls/data_buffer.hpp> #include <hls/streaming.hpp> #include <stdio.h> #define N 2048 using hls::DoubleBuffer; using hls::FIFO; using hls::ref; using hls::thread; // Reads input stream into array. void StreamToBuffer(FIFO<int> &in_fifo, DoubleBuffer<int[N]> &in_buffer) { auto &buf_array = in_buffer.producer(); // Obtain the reference to buffer. while (1) { in_buffer.producer_acquire(); // Acquire buffer to write output data. #pragma HLS loop pipeline for (int i = 0; i < N; i++) buf_array[i] = in_fifo.read(); in_buffer.producer_release(); // Release buffer to downstream. } } // Forward declare the MergeSortArray function. Implementation is shown below. void MergeSortArray(int in[N], int out[N]); // Performs merge sort whenever the input and output buffers become available. void MergeSort(DoubleBuffer<int[N]> &in_buffer, DoubleBuffer<int[N]> &out_buffer) { auto &in = in_buffer.consumer(); // Obtain the reference to input buffer. auto &out = out_buffer.producer(); // Obtain the reference to output buffer. while (1) { in_buffer.consumer_acquire(); // Acquire input buffer from upstream. out_buffer.producer_acquire(); // Acquire buffer for output. MergeSortArray(in, out); out_buffer.producer_release(); // Release output buffer to downstream. in_buffer.consumer_release(); // Release input buffer back to upstream. } } // Writes array into output stream. void BufferToStream(DoubleBuffer<int[N]> &out_buffer, FIFO<int> &out_fifo) { auto &buf_array = out_buffer.consumer(); // Obtain the reference to buffer. while (1) { out_buffer.consumer_acquire(); // Acquire buffer to read data from upstream. #pragma HLS loop pipeline for (int i = 0; i < N; i++) out_fifo.write(buf_array[i]); out_buffer.consumer_release(); // Release buffer back to upstream. } } // Top-level function implementing a pipeline that sorts data stream. void MergeSortPipeline(FIFO<int> &in_fifo, FIFO<int> &out_fifo) { // Create two buffers as the intermediate storage for the three threads/functions. DoubleBuffer<int[N]> in_buffer, out_buffer; thread<void>(StreamToBuffer, ref(in_fifo), ref(in_buffer)); thread<void>(MergeSort, ref(in_buffer), ref(out_buffer)); thread<void>(BufferToStream, ref(out_buffer), ref(out_fifo)); }
- The
StreamToBuffer,MergeSort, andBufferToStreamfunctions correspond to the blue function blocks in the above diagram.-
StreamToBufferreadsin_fifostream and writes toin_buffer,MergeSortreadsin_bufferand writes toout_buffer,BufferToStreamreadsout_bufferand writes toout_fifostream,each function calls the corresponding producer or consumer side methods to access the sharedDoubleBuffer, as described in the above section.
MergeSortPipelinefunction implements the dataflow pipeline, -
- the
in_fifoandout_fifoarguments correspond to the input and output streams of the pipeline,the intermediateDoubleBufferare instantiated:in_bufferandout_buffer, corresponding to the gray buffer blocks in the above diagram,the three processing functions are then invoked as parallel threads, and the input and output data are passed by reference to the threads (also see Supported HLS Thread APIs).
- the
- in each of the three processing functions, wrap the operations inside an infinite
while (1)loop; each loop iteration processes one segment of data,the three threads forked inMergeSortPipelinefunction are never joined and left constantly running.
- in each of the three processing functions, wrap the operations inside an infinite
- Now we have three free-running threads, each can start processing a new segment of data whenever the input/output storage becomes available to acquire via the
<producer|consumer>_acquire()methods.
In this design, each of the input and output buffers has two copies of storage for the 2048-element segment. By having two copies of storage in a double buffer, the upstream producer can write a new batch of output to one copy of storage, while the downstream consumer simultaneously processes the previous batch stored in the other copy of storage as input.
DoubleBuffer allows to overlap the executions of upstream and downstream threads.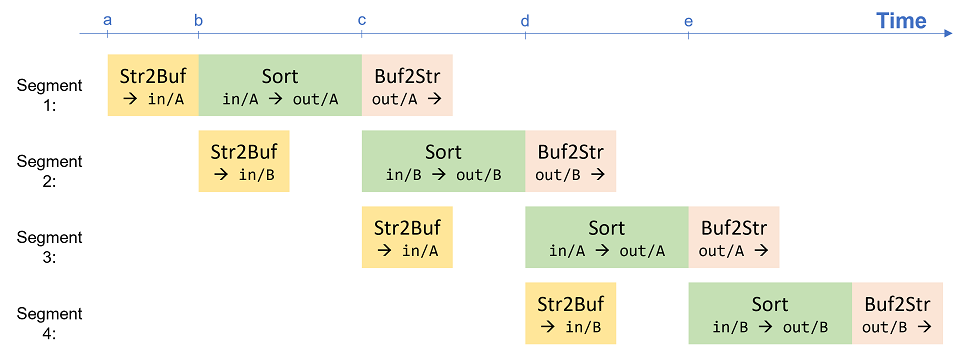
At time a, Str2Buf starts to receive input stream and store every 2048 input elements to storage A of input buffer (annotated as "in/A" in the figure).
- At time b, when
Str2Buffinishes storing the first segment,-
Sortstarts working on the input stored in storage A of input buffer, and saves sorted result into storage A of output buffer,meanwhileStr2Bufcan start storing the second segment to storage B of input buffer.
Sortfinishes sorting the first segment, -
- output buffer's storage A is released for
Buf2Strto send sorted segment to output stream,input buffer's storage A is freed up forStr2Bufto store the next segment (segment 3),and by this time,Str2Bufhas finished storing segment 2 into input buffer's storage B, soSortcan immediately start working on segment 2. - We assume
Sorttakes more time thanStr2Buf.
- We assume
Sortfinishes (e.g., at time c, d, and e),- output buffer's storage A is released for
- one input storage is released to the upstream
Str2Bufto store a new input segment,one output storage is released to the downstreamBuf2Strto stream out the sorted segment,theSortstage itself can work on the next segment immediately, the throughput of the dataflow pipeline is determined by the most time-consuming stage, i.e.,Sortin this case.
- one input storage is released to the upstream
SharedBuffer, by simply replacing all DoubleBuffer type with SharedBuffer type. When using SharedBuffer, each buffer has only one copy of storage, which can only be accessed by one function at a time. So two adjacent upstream and downstream functions cannot be both active simultaneously. The figure below shows the timeline when using SharedBuffer: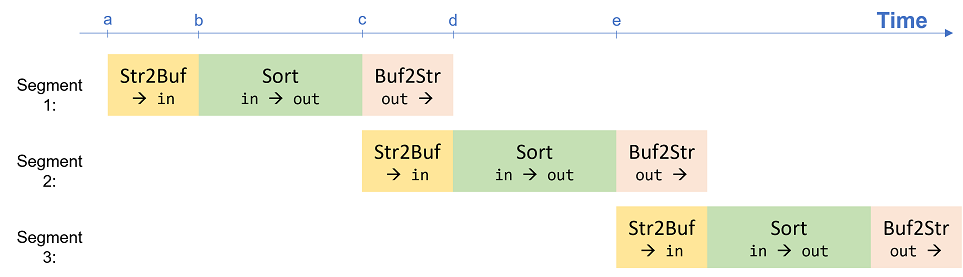
Notice at time b, when Str2Buf finishes writing a segment to input buffer, Str2Buf cannot immediately start writing the next segment as in the DoubleBuffer case. Str2Buf needs to wait until Sort finishes sorting at time c and releases the only input buffer storage, in order to start storing the next segment. Similarly, when Sort is running and has the output buffer acquired, the downstream Buf2Str has to wait.
In short, when Sort is running, its upstream Str2Buf and downstream Buf2Str have no available buffers to continue processing and have to wait; when Sort finishes, Str2Buf and Buf2Str can be both active (e.g., from time c to d), because they do not access common buffers.
In this case, the throughput of the dataflow pipeline is determined by the latency of Sort plus Str2Buf (or Buf2Str, whichever is longer).
For completeness, the code below implements the merge sort algorithm (MergeSortArray) and a main function injecting input and checking output to/from the dataflow pipeline. Note that,
- The
MergeOnePassfunction merges the multiple pairs of halves from one array into another array. TheMergeSortArraycallsMergeOnePassrepeatedly with a doubling partition size, and alternates the input and output array arguments between calls to reuse memory. The two arrays are the storage inside the input and output buffers. As you can see, the sort function, being the consumer of the input buffer, can also write to the buffer; and being the producer of the output buffer, can also read from the buffer. Since free-running threads (that are continuously running and never joined) are not supported by SW/HW Co-Simulation (limitation listed in Simulate HLS Hardware (SW/HW Co-Simulation)), we make themainfunction as the top-level to generate hardware for the entire program, so that theSimulate Hardware(shls sim) feature can run directly without a custom testbench.
// One pass of merge with partition_size -- merging multiple pairs of halves // across the whole array. // For each pair, merges the two haves in[l .. m] and in[m + 1 .. r] into out[l // .. r], where m = l + partition_size - 1, r = l + 2 * partition_size - 1 // Assume the array size is a power of 2. void MergeOnePass(int in[N], int out[N], int partition_size) { for (unsigned left_idx = 0; left_idx < N; left_idx += 2 * partition_size) { int m = left_idx + partition_size - 1, r = m + partition_size; // Indices in the input and output arrays. int i = left_idx, j = m + 1; #pragma HLS loop pipeline for (int k = left_idx; k < left_idx + 2 * partition_size; k++) { bool copy_i = (i > m) ? false : (j > r) ? true : in[i] < in[j]; if (copy_i) { out[k] = in[i]; i++; } else { out[k] = in[j]; j++; } } } } // Merge sort is done in multiple steps, each step merges on two partitions with // twice bigger the size of previous step. void MergeSortArray(int in[N], int out[N]) { // Each MergeOnePass merges from halves in array 'in' to 'out', then // alternates to merge halves in array 'out' to 'in'. // We can reuse the memory by alternating the in and out arrays. MergeOnePass(in, out, 1); MergeOnePass(out, in, 2); MergeOnePass(in, out, 4); MergeOnePass(out, in, 8); MergeOnePass(in, out, 16); MergeOnePass(out, in, 32); MergeOnePass(in, out, 64); MergeOnePass(out, in, 128); MergeOnePass(in, out, 256); MergeOnePass(out, in, 512); MergeOnePass(in, out, 1024); } #define TEST_ITERATIONS 10 int main() { #pragma HLS function top FIFO<int> in_fifo(TEST_ITERATIONS * N), out_fifo(TEST_ITERATIONS * N); for (int i = 0; i < TEST_ITERATIONS * N; i++) in_fifo.write(TEST_ITERATIONS * N - 1); MergeSortPipeline(in_fifo, out_fifo); unsigned err_cnt = 0; for (int n = 0; n < TEST_ITERATIONS; n++) { int last = out_fifo.read(); for (int i = 1; i < N; i++) { int cur = out_fifo.read(); if (last > cur) { printf("i: %d, last (%d) > cur (%d)\n", i, last, cur); err_cnt += 1; } last = cur; } } if (err_cnt) printf("FAIL. err_cnt = %d\n", err_cnt); else printf("PASS. err_cnt = %d\n", err_cnt); return err_cnt; }